
Nguồn
![]() System Design: Why is Kafka so Popular?
System Design: Why is Kafka so Popular?
![]() Top Kafka Use Cases You Should Know
Top Kafka Use Cases You Should Know
Giới thiệu
Kafka ban đầu là một công cụ xử lý log của LinkedIn. Từ đó, nó tiến hóa để trở thành một nền tảng xử lý dòng sự kiện trong hệ thống phân tán.
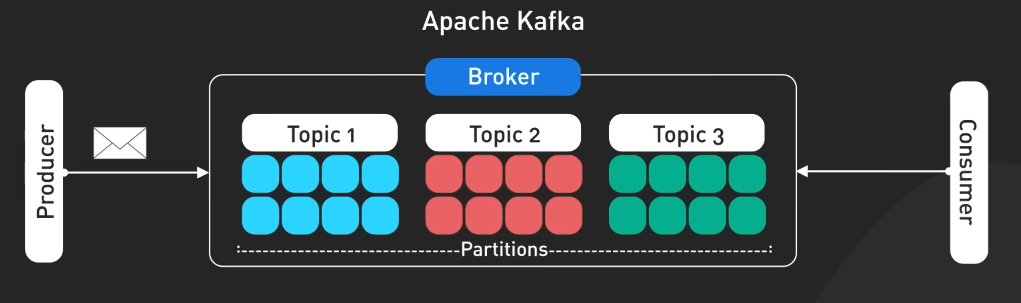
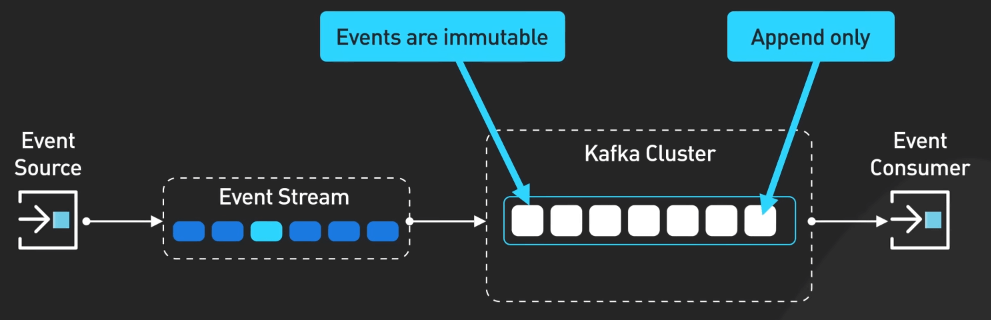
Thiết kế của Kafka tận dụng các append-only log với cấu trúc dữ liệu cố định và các cơ chế lưu trữ có thể cấu hình được. Những điều này khiến cho Kafka trở thành một lựa chọn tuyệt với cho nhiều ứng dụng vượt qua cả thiết kế ban đầu.
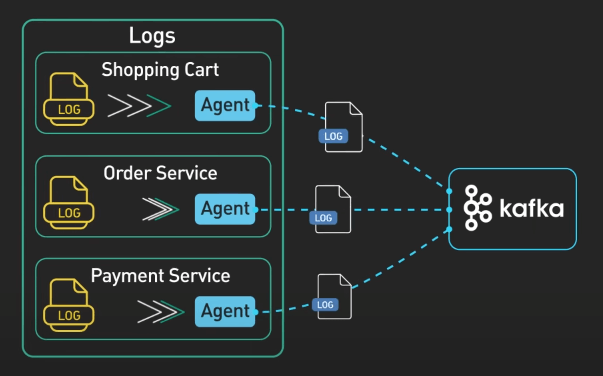
Xử lý và phân tích log
Phân tích log giờ đây không còn chỉ là về xử lý log nữa, mà đã trở thành việc tập trung và phân tích log từ hệ thống phân tán phức tạp trong thời gian thực. Kafka tỏa sáng vì nó có thể tiêu thụ log từ nhiều nguồn khác nhau một cách đồng thời, ví dụ như các ứng dụng, microservice, cloud service, và hệ thống cơ sở dữ liệu. Nó có khả năng xử lý lượng lớn log mà vẫn giữ độ trễ ở mức thấp.
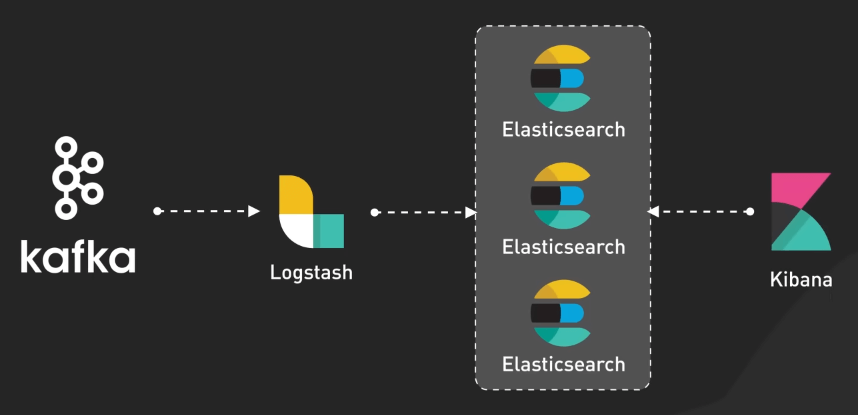
Điều giúp việc phân tích log ngày nay trở nên mạnh mẽ là nhờ việc Kafka tích hợp thêm các công cụ như ElasticSearch, Logstash, và Kibana. Bộ ba này được gọi là ELK stack. Logstash sẽ kéo log từ Kafka về, xử lý chúng và gửi cho ElasticSearch. Kibana sẽ cho phép dev team trực quan hóa và phân tích các log này theo thời gian thực.
Pipeline cho Machine Learning theo thời gian thực
Các hệ thống Machine Learning hiện đại cần xử lý rất nhiều dữ liệu một cách nhanh chóng và liên tục. Khả năng xử lý dữ liệu streaming của Kafka giúp nó trở thành một công cụ lý tưởng cho việc xây dựng pipeline cho Machine Learning theo thời gian thực. Kafka đóng vai trò then chốt trong pipeline này, nó tiêu thụ dữ liệu từ nhiều nguồn như tương tác người dùng, các thiết bị IoT hay các giao dịch tài chính. Dữ liệu này sau đó được chuyển đến các model Machine Learning trong thời gian thực.
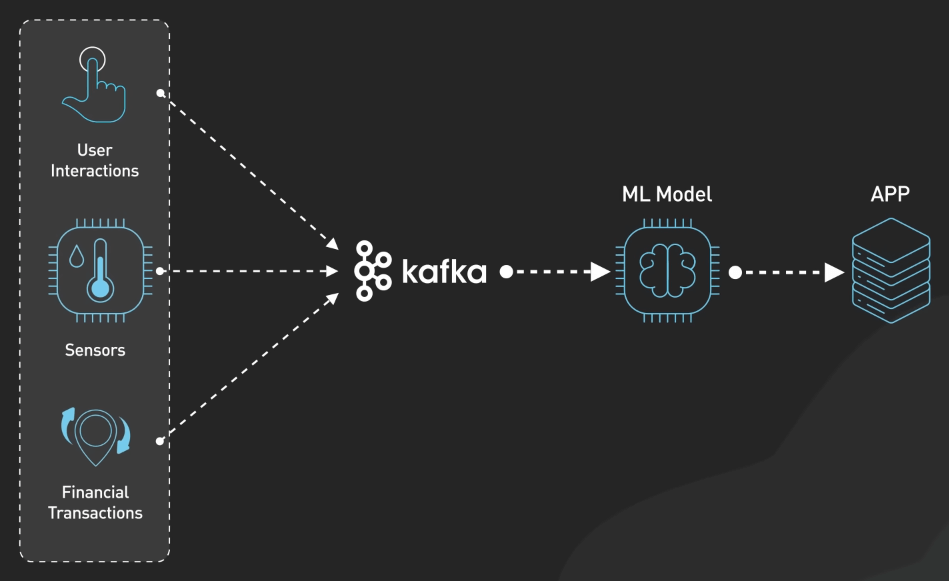
Ví dụ, trong một hệ thống phát hiện gian lận tài chính, Kafka sẽ stream dữ liệu giao dịch đến các model. Các model này sẽ giúp phát hiện các hoạt động đáng ngờ ngay lập tức. Trong bảo trì dự đoán (predictive maintenance), Kafka sẽ stream dữ liệu từ các thiết bị IoT đến các model Machine Learning. Các model này sẽ dự đoán khi nào thiết bị cần bảo trì, giúp giảm thiểu thời gian chết và chi phí bảo trì.
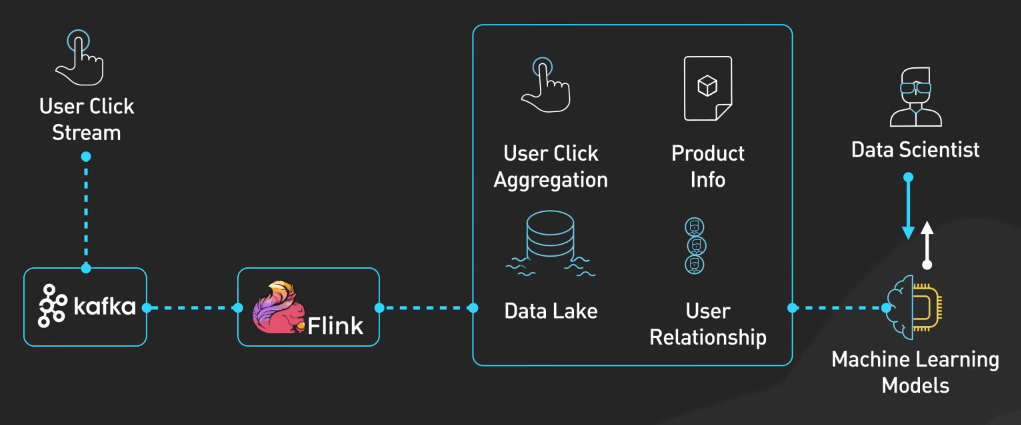
Kafka có tích hợp được với các framework xử lý stream như Apache Flink hay Spark Streaming. Các công cụ này có thể đọc dữ liệu từ Kafka, sau đó thực hiện các tính toán phức tạp và cuối cùng gửi kết quả về lại Kafka hoặc sang một hệ thống khác.
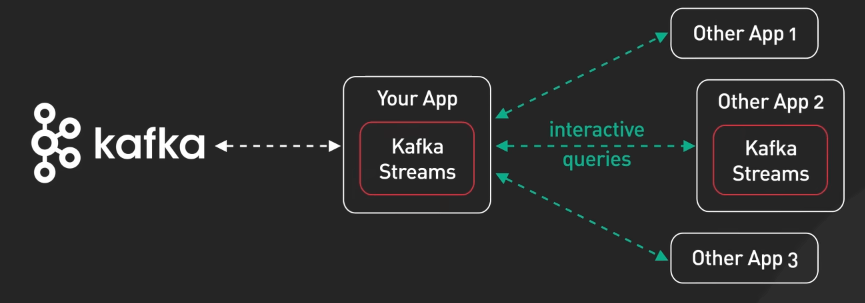
Ta cũng cần nhắc đến Kafka Stream, một thư viện xử lý stream được xây dựng trên Kafka. Kafka Stream giúp xây dựng các ứng dụng xử lý stream một cách dễ dàng và hiệu quả.
Giám sát và cảnh báo hệ thống
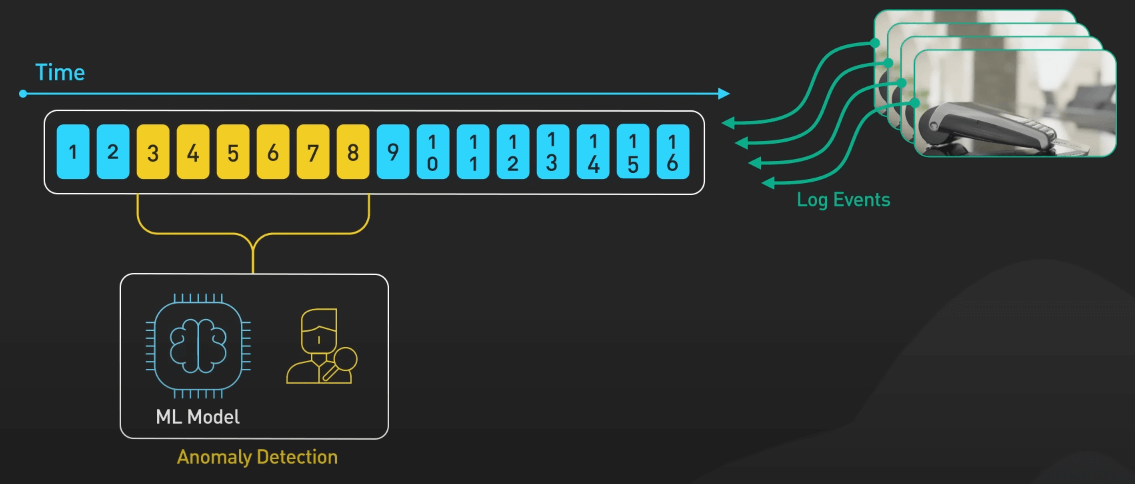
Với sự phức tạp ngày càng tăng của các hệ thống, việc phát hiện và giải quyết vấn đề một cách chủ động là điều rất cần thiết. Kafka tiếp nhận các metric và sự kiện từ nhiều service khác nhau. Cái khác biệt ở đây là việc xử lý các metric này theo thời gian thực. Từ Kafka, các công cụ xử lý stream như Flink có thể phân tích dữ liệu liên tục, như tính toán các giá trị tổng hợp, phát hiện bất thường, hay kích hoạt cảnh báo, tất cả trong thời gian thực.
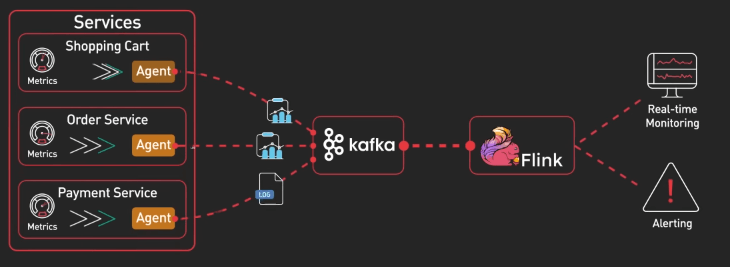
Kafka PubSub rất phù hợp ở đây, vì nó cho phép nhiều consumer xử lý cùng một stream metric mà không ảnh hưởng đến nhau. Các consumer có thể bao gồm: 1 cái để cập nhật dashboard, 1 cái quản lý cảnh báo, và một cái có thể gửi dữ liệu cho một cái model Machine Learning.
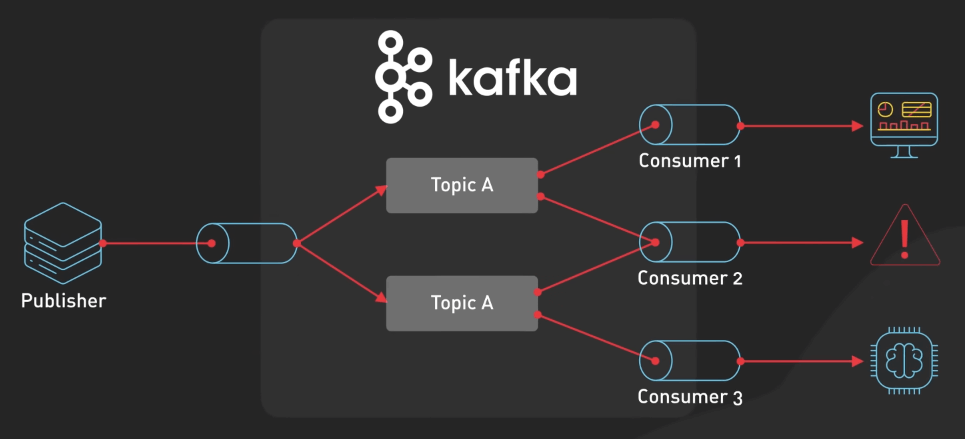
Ngoài ra, ta có thể debug với Kafka vì ta có thể tái tạo lại các sự kiện đã xảy ra, nghĩa là tạo lại y hệt stream metric mà ta muốn debug.
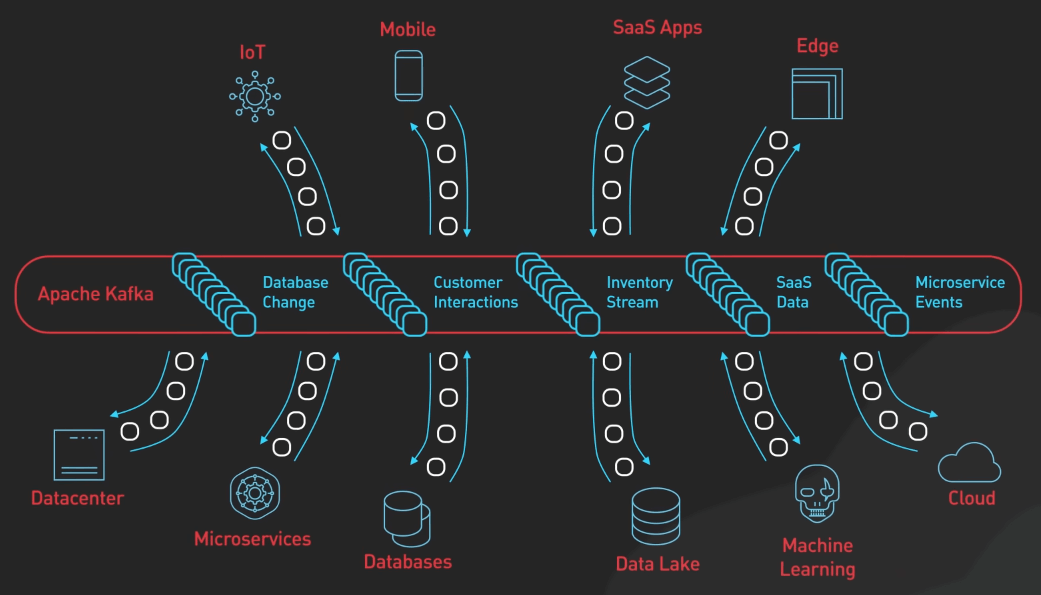
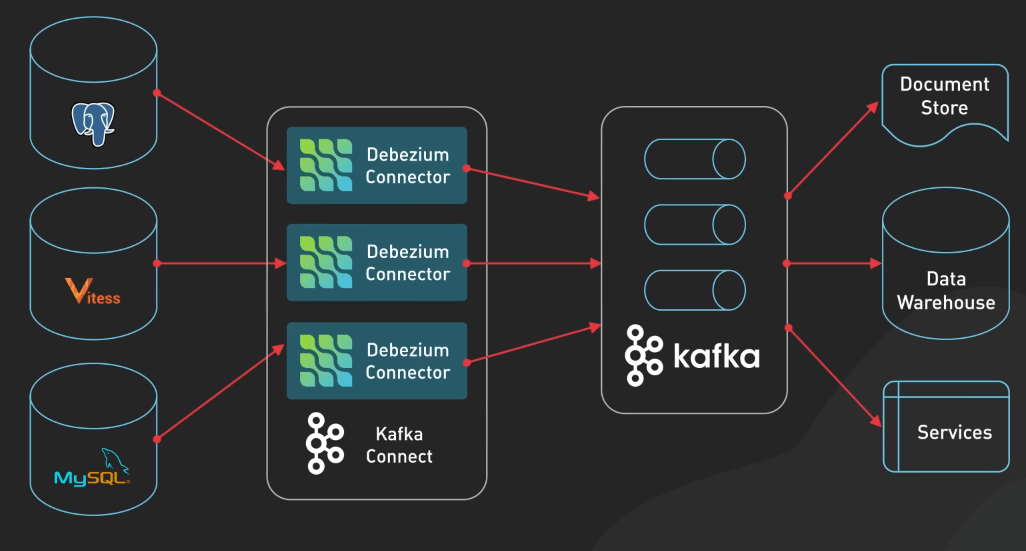
Change Data Capture (CDC)
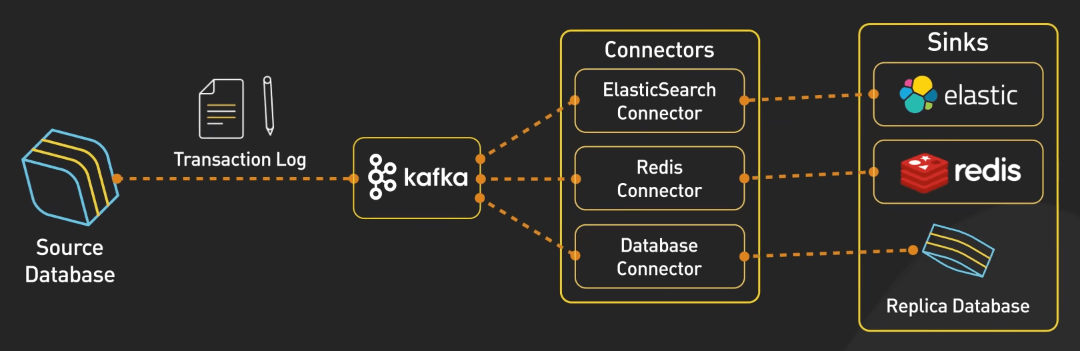
CDC là phương pháp được dùng để theo dõi và ghi lại các thay đổi trong cơ sở dữ liệu, cho phép sao chép các thay đổi này đến các hệ thống khác trong thời gian thực. Trong kiến trúc này, Kafka đóng vai trò trung tâm giúp chuyển thay đổi trong cơ sở dữ liệu nguồn đến các hệ thống khác một cách đồng bộ và nhất quán.
Quá trình bắt đầu với cơ sở dữ liệu nguồn, đây là các cơ sở dữ liệu chính nơi các thay đổi xảy ra. Các database này sẽ tạo ra các transaction log, lưu giữ toàn bộ các thay đổi dữ liệu, như chèn, cập nhật hay xóa theo thứ tự thời gian. Các log này sẽ được đưa vào Kafka.
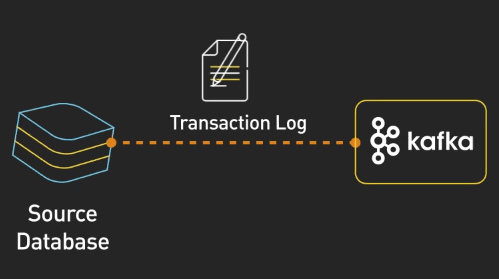
Kafka lưu các sự kiện thay đổi này theo các topic, cho phép nhiều consumer đọc dữ liệu từ các topic này.
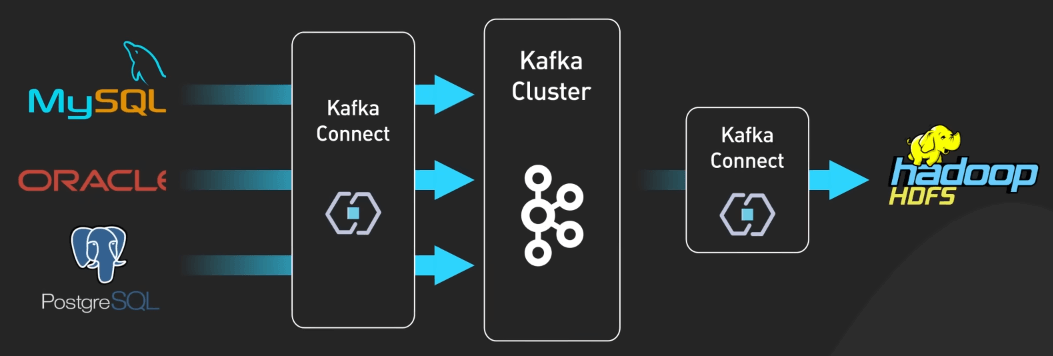
Để di chuyển dữ liệu từ Kafka đến các hệ thống khác, ta cần sử dụng Kafka Connect. Framework này cho phép ta build và chạy nhiều connector. Ví dụ, ta có thể có ElasticSearch Connector để chuyển dữ liệu từ Kafka đến ElasticSearch, hoặc Redis Connector để chuyển dữ liệu từ Kafka đến Redis.
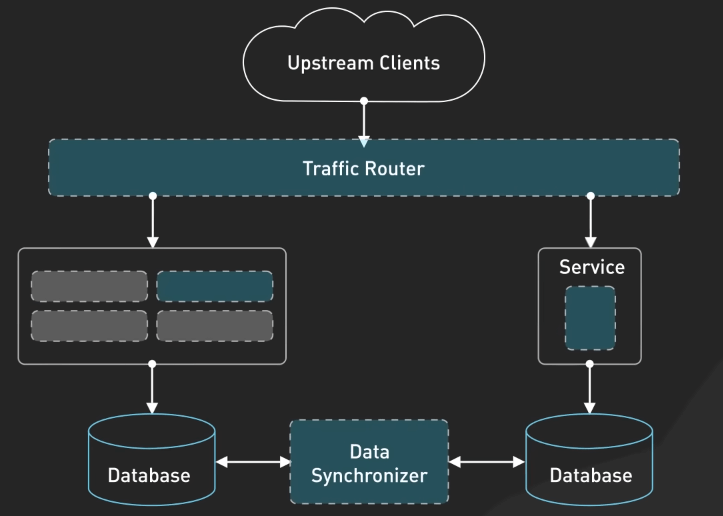
Di chuyển hệ thống
Kafka có thể đóng vai trò như một buffer giữa hệ thống cũ và mới, cho phép dữ liệu chuyển đổi một cách mượt mà và an toàn.
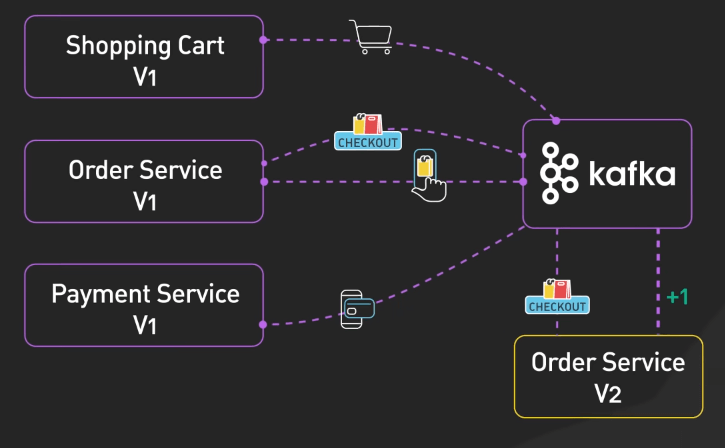
Kafka cho phép dev triển khai nhiều cách di chuyển hệ thống phức tạp.
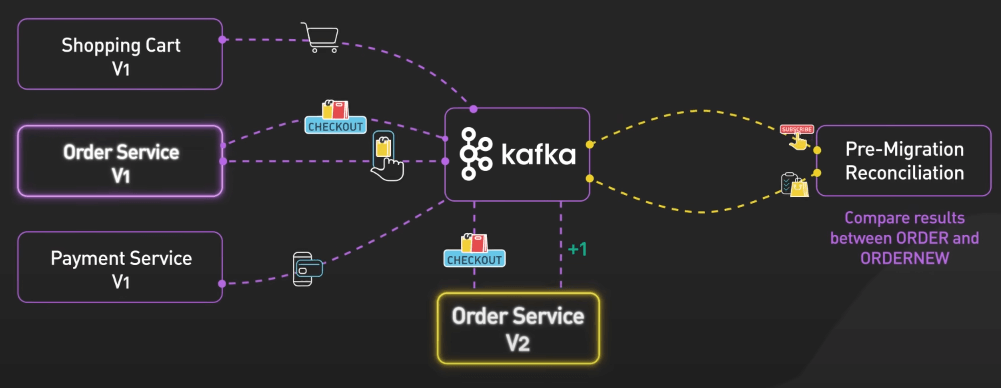
Kafka có thể gửi lại các message tại bất cứ thời điểm cụ thể nào, giúp dev team kiểm tra tính nhất quán giữa hệ thống cũ và mới. Ta thậm chí có thể sử dụng cả hai phiên bản hệ thống cùng một lúc, cho phép so sánh kết quả giữa chúng và rollback nếu cần.
Website không chứa bất kỳ quảng cáo nào, mọi đóng góp để duy trì phát triển cho website (donation) xin vui lòng gửi về STK 90.2142.8888 - Ngân hàng Vietcombank Thăng Long - TRAN VAN BINH
=============================
Nếu bạn không muốn bị AI thay thế và tiết kiệm 3-5 NĂM trên con đường trở thành DBA chuyên nghiệp hay làm chủ Database thì hãy đăng ký ngay KHOÁ HỌC ORACLE DATABASE A-Z ENTERPRISE, được Coaching trực tiếp từ tôi với toàn bộ bí kíp thực chiến, thủ tục, quy trình của gần 20 năm kinh nghiệm (mà bạn sẽ KHÔNG THỂ tìm kiếm trên Internet/Google) từ đó giúp bạn dễ dàng quản trị mọi hệ thống Core tại Việt Nam và trên thế giới, đỗ OCP.
- CÁCH ĐĂNG KÝ: Gõ (.) hoặc để lại số điện thoại hoặc inbox https://m.me/tranvanbinh.vn hoặc Hotline/Zalo 090.29.12.888
- Chi tiết tham khảo:
https://bit.ly/oaz_w
=============================
2 khóa học online qua video giúp bạn nhanh chóng có những kiến thức nền tảng về Linux, Oracle, học mọi nơi, chỉ cần có Internet/4G:
- Oracle cơ bản: https://bit.ly/admin_1200
- Linux: https://bit.ly/linux_1200
=============================
KẾT NỐI VỚI CHUYÊN GIA TRẦN VĂN BÌNH:
📧 Mail: binhoracle@gmail.com
☎️ Mobile/Zalo: 0902912888
👨 Facebook: https://www.facebook.com/BinhOracleMaster
👨 Inbox Messenger: https://m.me/101036604657441 (profile)
👨 Fanpage: https://www.facebook.com/tranvanbinh.vn
👨 Inbox Fanpage: https://m.me/tranvanbinh.vn
👨👩 Group FB: https://www.facebook.com/groups/DBAVietNam
👨 Website: https://www.tranvanbinh.vn
👨 Blogger: https://tranvanbinhmaster.blogspot.com
🎬 Youtube: https://www.youtube.com/@binhguru
👨 Tiktok: https://www.tiktok.com/@binhguru
👨 Linkin: https://www.linkedin.com/in/binhoracle
👨 Twitter: https://twitter.com/binhguru
👨 Podcast: https://www.podbean.com/pu/pbblog-eskre-5f82d6
👨 Địa chỉ: Tòa nhà Sun Square - 21 Lê Đức Thọ - Phường Mỹ Đình 1 - Quận Nam Từ Liêm - TP.Hà Nội
=============================
cơ sở dữ liệu, cơ sở dữ liệu quốc gia, database, AI, trí tuệ nhân tạo, artificial intelligence, machine learning, deep learning, LLM, ChatGPT, DeepSeek, Grok, oracle tutorial, học oracle database, Tự học Oracle, Tài liệu Oracle 12c tiếng Việt, Hướng dẫn sử dụng Oracle Database, Oracle SQL cơ bản, Oracle SQL là gì, Khóa học Oracle Hà Nội, Học chứng chỉ Oracle ở đầu, Khóa học Oracle online,sql tutorial, khóa học pl/sql tutorial, học dba, học dba ở việt nam, khóa học dba, khóa học dba sql, tài liệu học dba oracle, Khóa học Oracle online, học oracle sql, học oracle ở đâu tphcm, học oracle bắt đầu từ đâu, học oracle ở hà nội, oracle database tutorial, oracle database 12c, oracle database là gì, oracle database 11g, oracle download, oracle database 19c/21c/23c/23ai, oracle dba tutorial, oracle tunning, sql tunning , oracle 12c, oracle multitenant, Container Databases (CDB), Pluggable Databases (PDB), oracle cloud, oracle security, oracle fga, audit_trail,oracle RAC, ASM, oracle dataguard, oracle goldengate, mview, oracle exadata, oracle oca, oracle ocp, oracle ocm , oracle weblogic, postgresql tutorial, mysql tutorial, mariadb tutorial, ms sql server tutorial, nosql, mongodb tutorial, oci, cloud, middleware tutorial, docker, k8s, micro service, hoc solaris tutorial, hoc linux tutorial, hoc aix tutorial, unix tutorial, securecrt, xshell, mobaxterm, putty